База знаний
База знаний  IP-АТС
IP-АТС  Оборудование
Оборудование  О нас
О нас Кластеризация
Вы не можете съесть гроздь винограда сразу,
но очень легко вы съедите их одну за другой.
—Жак Румен
Слово «кластеризация» может означать разные вещи для разных людей. Некоторые люди скажут, что кластеризация — это просто наличие реплицируемой системы в режиме ожидания, доступной для включения при сбое основной. Для других кластеризация предполагает наличие нескольких систем, работающих совместно друг с другом, с реплицированными данными, полностью избыточными и бесконечно расширяемыми. Для большинства людей истина, вероятно, где-то между этими двумя крайностями.
В этой главе мы рассмотрим возможности кластеризации, которые существуют в Asterisk на высоком уровне и дадим вам знания и направления для планирования вашей системы в будущем. В качестве примеров мы рассмотрим некоторые инструменты, которые мы использовали в наших собственных крупных развертываниях. Хотя нет единого способа создания кластера Asterisk, топологии, которые мы рассмотрим, оказались надежными и популярными с течением времени.
Наши примеры будут углубляться в создание распределенного центра обработки вызовов, одной из наиболее популярных причин построения распределенной системы. В некоторых случаях это необходимо просто потому, что у компании есть вспомогательные офисы, которые она хочет связать с первичной системой. Для других цель состоит в том, чтобы интегрировать удаленных сотрудников или иметь возможность обрабатывать большое количество мест. Мы начнем с простых, традиционных УАТС, и посмотрим, как эта система в конечном итоге может перерасти в нечто гораздо большее.
DevOps: автоматическое развертывание
В последнее время в моде облачные вычисления, это новые унифицированные коммуникации! Однако, в отличие от унифицированных коммуникаций, облачные вычисления, кажется, погружены в реальную разработку и уже произвели большое количество функциональных возможностей (см. OpenStack) и даже создали целые организации (см. Amazon Web Services и тому подобные).
Но нам нужен способ управлять всеми этими распределенными системами и огромной вычислительной мощностью. Обычно многие администраторы создают документацию, bash скрипты и другие пользовательские средства, которые помогают им развертывать системы и управлять ими. Конечно, это становится громоздким, когда вы начинаете масштабировать, и в конечном итоге вам нужно больше людей чтобы помочь поддерживать системы.
Ввод DevOps. Менталитет DevOps — это воспроизводимость до крайности. Используя фреймворк, который позволяет описать как должны выглядеть ваши системы (или, скорее, что должно быть установлено на основе роли, которую система играет в вашей сети), вы сможете лучше масштабироваться и выходить за пределы без головной боли обслуживания несопоставимых систем. Это всегда было важно, но с появлением облачных вычислений потребность современных администраторов становится еще более насущной.
Есть несколько различных систем, которые вы можете использовать, наиболее популярными являются Puppet от PuppetLabs и Chef от Opscode. Обе делают по существу то же самое, но с использованием отдельного синтаксиса (Puppet имеет свой собственный доменный язык; Chef использует родной Ruby с дополнительными расширениями). Покрутите каждую, посмотрите несколько видео и решите для себя, какую из них вы предпочтете. Обе — удивительные подвиги системной инженерии.
На AstriCon 2012 пол Белангер из Polybeacon и Лейф Мэдсен говорили о DevOps, давая обзор DevOps в среде Asterisk.
Традиционные УАТС
Большинство систем УАТС, развернутых до 2000 года, выглядят очень похоже. Как правило, они включают в себя группу телефонных линий, поставляемых либо через PRI, либо через массив аналоговых линий, соединяющих внешний мир через УАТС, с группой фирменных телефонов и периферийных приложений. Эти системы предоставляют общий набор функций УАТС с дополнительными возможностями, такими как голосовая почта и конференц-связь, предоставляемые через внешние аппаратные модули (обычно это добавляет тысячи долларов к стоимости системы). Эта топология показана на Рисунке 22-1.
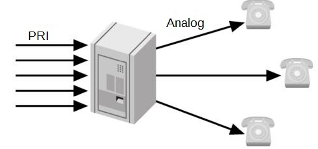
Такие системы используют набор правил для доставки вызовов операторам через стандартные правила автоматического распределения вызовов (ACD) и имеют небольшую гибкость. Вероятно, либо невозможно, либо дорого добавить удаленных агентов так как вызовы должны приходить по ТфОП, которая использует две телефонные линии: одну для входящего звонящего в очередь, а другую для доставки удаленному агенту (в большинстве случаев агенты просто должны находиться в том же физическом местоположении, что и сама АТС).
Однако эти традиционные телефонные системы постепенно вытесняются, поскольку все больше людей начинают требовать использования функций VoIP. И даже для систем, которые не будут использовать VoIP, такие решения, как Asterisk, предлагают функции, которые когда-то стоили тысячи долларов как включенная часть программного обеспечения.
Конечно, с деньгами, вложенными в дорогостоящее оборудование в традиционные АТС, естественно, что организации захотят пользоваться этими системами как можно больше. Кроме того, простая замена существующей системы не только дорога (затраты на проводку для SIP-телефонов, затраты на замену проприетарных телефонных трубок и т.д.), но и может нарушить работу call-центра, особенно если он работает непрерывно.
Однако, возможно пришло время для расширения, и существующая система больше не в состоянии идти в ногу с количеством необходимых линий и количеством мест, необходимых для удовлетворения спроса. В этом случае, может быть выгодно взглянуть на гибридную систему, где существующее оборудование продолжает использоваться, но новые места и функции добавляются в систему с использованием Asterisk.
Гибридные системы
Гибридная телефонная система (Рисунок 22-2) содержит те же функциональные возможности и аппаратное обеспечение, что и традиционная телефонная система, но к ней подключена другая система, например Asterisk, что обеспечивает дополнительную емкость и функциональность. Добавление Asterisk в традиционную систему обычно выполняется через соединение PRI. С точки зрения традиционной системы Asterisk будет выглядеть как телефонная компания (центральный офис или ЦO). В зависимости от того, как работает традиционная система, и услуг, доступных для или из ЦO, либо Asterisk будет доставлять вызовы от PRI через себя на существующую УАТС, либо существующая УАТС будет отправлять вызовы через соединение PRI в Asterisk, которая затем будет направлять звонки на новые конечные точки (телефоны).

На рисунке — с помощью Asterisk функциональность может быть перемещена по частям из существующей системы УАТС на Asterisk, который может взять на себя большую роль и управлять большей частью системы с течением времени. В конце концов, существующая УАТС может просто использоваться как метод для отправки вызовов на существующие телефоны на рабочих столах агентов, с тем расчетом, что со временем они могут быть заменены на SIP-телефоны, так как проводка и телефоны закуплены.
Добавив Asterisk в существующую систему, мы получаем новый набор функциональных возможностей и преимуществ, таких как:
- Поддержка удаленных сотрудников с осуществлением вызовов через существующее подключение к интернету
- Такие функции, как конференц-связь и голосовая почта (с возможностью уведомления пользователей по электронной почте о новых сообщениях)
- Расширенные телефонные линии с использованием VoIP, а также снижение затрат на междугороднюю связь
Такая система по-прежнему имеет ряд недостатков, поскольку все оборудование должно находиться в call-центре, и мы, по-прежнему, ограничены использованием дорогостоящего (относительно) оборудования в системе Asterisk для подключения к традиционной УАТС. Тем не менее, мы движемся в правильном направлении и с системой Asterisk мы можем начать миграцию с течением времени, ограничивая перерывы в бизнесе и применяя более постепенный подход к обучению пользователей.
Чистый Asterisk, нераспределенный
Следующим шагом в нашем путешествии является чистая система Asterisk. В этой системе мы успешно перешли от существующей системы УАТС и теперь обрабатываем все функции через Asterisk. Наш существующий PRI был присоединен к Asterisk, и мы расширили наши возможности за счет интеграции в систему поставщика услуг интернет-телефонии (ITSP). Все агенты теперь используют SIP-телефоны, и мы даже добавили несколько удаленных сотрудников. Эта топология показана на Рисунке 22-3.

Удаленные сотрудники могут быть большим преимуществом для компании. Мало того, что позволяя вашим сотрудникам работать из отдаленных мест вы повышаете их моральный дух, облегчая бремя потенциально длительных поездок на работу, так же это позволяет людям работать в среде, в которой они чувствуют себя комфортно, что может сделать их более продуктивными. Кроме того, менеджер колл-центра не имеет меньшего контроля над статистикой сотрудников: звонки удаленных работников по-прежнему могут контролироваться в учебных целях, а собранные статистические данные не отличаются от данных, полученных менеджером, чем для сотрудников, работающих на месте.
Измеримым преимуществом для компании является уменьшение количества оборудования, необходимого каждому сотруднику. Если агенты могут использовать свои существующие компьютерные системы, электрические сети и интернет-соединения, компания может сэкономить значительную сумму денег, поддерживая удаленных сотрудников. Кроме того, эти сотрудники могут быть расположены по всему миру, что увеличит количество часов, доступных вашим агентам и позволит вам обслуживать больше часовых поясов.
Использование этой системы является простым и эффективным, но по мере роста компании, система может достичь проблемы мощности. Мы рассмотрим как система может быть расширена в этой главе позже.
Asterisk и интеграция базы данных
Интеграция Asterisk с базой данных может добавить много функциональных возможностей в вашу систему. Кроме того, она позволяет создавать веб-утилиты настройки для упрощения обслуживания системы Asterisk. Более того, обеспечивает мгновенный доступ к информации из диалплана и других частей системы Asterisk.
Единая база данных
Добавление интеграции базы данных в Asterisk (Рисунок 22-4) — это мощный способ получить доступ к информации, которой можно манипулировать другими средствами. Например, мы можем считывать информацию о внутренних номерах и устройствах в системе из базы данных, используя архитектуру Asterisk Realtime (обсуждается в Главе 16), и можем изменять информацию, хранящуюся в базе данных, через внешнюю систему, такую как веб-страница.
Интеграция с базой данных добавляет слой между Asterisk и веб-интерфейсом, с которым знаком веб-дизайнер, и позволяет манипулировать данными таким образом, который не требует новых навыков. Знание самого Asterisk остается за администратором Asterisk, и веб-разработчик может с радостью работать с инструментами, с которыми он знаком.
Конечно, это делает систему Asterisk несколько более сложной для построения, но интеграция с базой данных через ODBC добавляет новые возможности (такие как hot-desking, обсуждаемый в разделе «Веселимся с func_odbc: горячий стол» в Главе 16). func_odbc — это мощный инструмент для администратора Asterisk, предоставляющий возможность строить статический диалплан с использованием данных, которые по своей природе являются динамическими. См Главу 16 для получения дополнительной информации о том, как интегрировать Asterisk с базой данных и предоставляемыми ею функциональными возможностями.
Нам также очень нравится модуль func_curl, который обеспечивает интеграцию с веб-сервисами по HTTP напрямую с диалпланом.
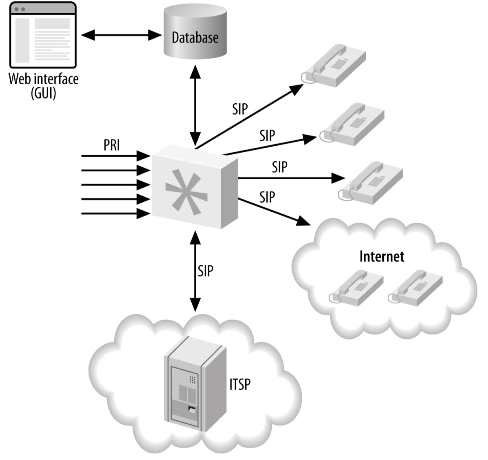
С данными, абстрагированными непосредственно от Asterisk, нам будет проще перейти к системе, которая готовится к кластеризации. Мы можем использовать что-то вроде LinuxHA для обеспечения автоматической отработки отказа между системами. В то время, как в случае сбоя вызовы в системе, которая отказала, будут потеряны, отработка отказа займет несколько мгновений (меньше секунды), чтобы система снова стала немедленно доступна своим пользователям. В этой конфигурации, поскольку наши данные абстрагируются за пределами Asterisk, мы можем использовать такие приложения, как unison или rsync, чтобы синхронизировать файлы конфигурации между основной и резервной системами. Мы также можем использовать subversion или git для отслеживания изменений в файлах конфигурации, что упрощает откат изменений, которые не работают.
Конечно, если наша база данных исчезнет из-за сбоя оборудования или программного обеспечения, наша система будет недоступна, если не будет запрограммирована таким образом, чтобы иметь возможность работать без подключения к базе данных. Это может быть достигнуто либо с помощью локальной базы данных, которая периодически обновляется из основной, либо с помощью информации, запрограммированной непосредственно в диалплане. В большинстве случаев функциональность системы в этом режиме будет ниже, чем когда база данных была доступна, но, по крайней мере, система не будет полностью непригодна для использования.
Лучшим решением было бы использовать реплицированную базу данных, которая позволяет одновременно писать данные, записанные на сервер базы данных, на другой сервер. После этого Asterisk может автоматически переключиться на другую базу данных, если основной сервер станет недоступен.
Реплицированные базы данных
Использование реплицированной базы данных обеспечивает некоторую избыточность в бэкэнде, чтобы ограничить время простоя вызывающих абонентов и агентов в случае сбоя базы данных. Конфигурация базы данных master-master необходима, чтобы данные могли быть записаны в любую базу данных и автоматически реплицированы в другую систему, гарантируя существования точной копии данных на двух физических машинах. Еще одним преимуществом такого подхода является то, что одной системе больше не нужно обрабатывать все транзакции в базу данных; нагрузку можно разделить между серверами. Рисунок 22-5 иллюстрирует эту распределенную структуру.
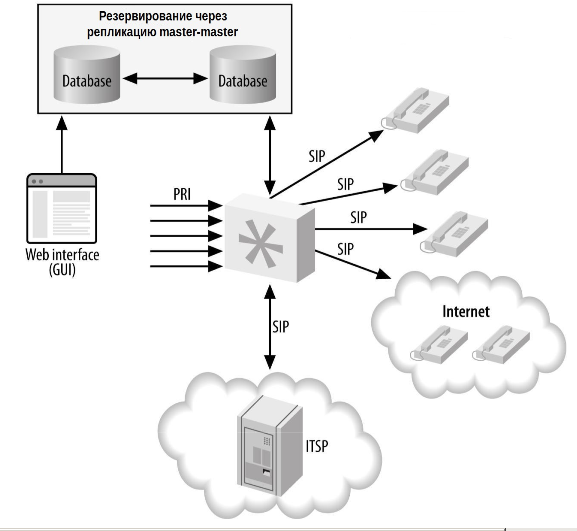

Мы уже использовали репликацию MySQL master-master раньше, и она работает довольно хорошо. Это также не так трудно настроить, и несколько учебников доступны в Интернете. Также стоит отметить, что репликация master-master — это обходной путь для двух репликаций master-slave, например:
host1.master —> host2.slave
host1.slave <— host2.slave
Это работает довольно хорошо, когда у вас есть только два сервера, но по мере того, как вы начинаете расти и расширяться и требовать еще больше серверов баз данных, вам нужны более тяжелые технологии, такие как MySQL Cluster или Galera Cluster for MySQL.
Другие системы баз данных, вероятно, также будут содержать эту функциональность, особенно если вы используете коммерческую систему, такую как Oracle или MS SQL.
Отработку отказа можно выполнить в Asterisk, так как res_odbc и func_odbc1 содержат параметры конфигурации, позволяющие указать несколько баз данных. В res_odbc можно указать предпочтительный порядок подключения к базе данных в случае сбоя. В func_odbc можно даже указать различные серверы для чтения и записи данных с помощью создаваемых функций диалплана. Вся эта гибкость позволяет вам обеспечить систему, которая работает хорошо для вашего бизнеса.
Внешние программы также можно использовать для управления отработкой отказа между системами. Приложение pen — это балансировщик нагрузки для простых TCP-приложений, таких как HTTP или SMTP, который позволяет нескольким серверам отображаться как один. Это означает, что Asterisk необходимо настроить для подключения только к одному IP-адресу (или имени хоста); приложение pen будет контролировать, какой сервер будет использоваться для каждого запроса.
Asterisk и предоставление статуса устройства
Состояния устройств в Asterisk являются важными как с точки зрения программного обеспечения (Asterisk нужно знать состояние устройства или линии на устройстве для того, чтобы узнать, возможно ли совершить вызов через нее) и с точки зрения пользователей (например, индикатор может быть включен или выключен, чтобы показать, является ли конкретная линия занятой или же агент доступен для любых звонков). С точки зрения очереди чрезвычайно важно знать статус устройства, которое использует агент, чтобы определить, может ли следующий абонент в очереди быть распределен этому агенту. Без знания состояния устройства очередь просто выполняла бы несколько вызовов к одной и той же конечной точке.
Как только вы начнете расширять свою единую систему до нескольких блоков (потенциально в нескольких физических местоположениях, таких как удаленные или вспомогательные офисы), вам нужно будет распределить состояния устройств конечных точек между системами. Тип реализации, которая требуется, будет зависеть от того, распределяете ли вы их между системами в той же локальной сети (каналы с низкой задержкой) или по глобальной сети (каналы с более высокой задержкой). Мы обсудим два метода распределения состояний устройств в данном разделе: Corosync для низких задержек связи и XMPP при высоких задержках.
Распределение состояний устройств по локальной сети
Реализация Corosync (ранее OpenAIS) была впервые добавлена к Asterisk в ветви 1.6.1, чтобы обеспечить распространение информации о состоянии устройств между серверами. Добавление Corosync обеспечило большие возможности для распределенных систем, так как осведомленность о состоянии устройств является важным аспектом таких систем. Предыдущие методы требовали использования GROUP() и GROUP_COUNT() для каждого канала, с этой информацией, запрашиваемой для распределенного универсального распознавания номеров (DUNDi). В то время как этот подход полезен в некоторых сценариях (мы могли бы использовать эту функциональность для поиска количества вызовов, которые наши системы обрабатывают и направляют вызовы разумно системам, обрабатывающим меньшее количество вызовов), в качестве механизма определения информации о состоянии устройства, которого ему крайне не хватает.
Corosync действительно дал нам первую реализацию системы, которая позволяет распределять состояния устройств и индикаторы сообщений ожидания между несколькими системами Asterisk (см. Рисунок 22-6). Недостатком реализации Corosync является то, что она требует чтобы все системы работали по каналам с низкой задержкой, что, как правило, означает, что все они должны находиться в одном физическом месте и быть подключены к одному коммутатору. Тем не менее, хотя библиотека Corosync не работает в физически раздельных сетях, она позволяет Queue() находиться в одной системе, а участникам очереди — в другой (или нескольких системах). Он делает это, не требуя от нас использования локальных каналов и проверки их доступности другими способами, тем самым ограничивая (или исключая) количество попыток подключения по сети и звонки с нескольких устройств.
Использование Corosync имеет преимущество в том, что его относительно легко настроить и начать работать. Недостатком является то, что он не распространяется по физическим локациям, хотя мы можем использовать XMPP для распределения состояния устройств по глобальной сети, как вы увидите в следующем разделе.
Дополнительную информацию о настройке распределенных состояний устройств с помощью Corosync можно найти в разделе «Использование Corosync» в Главе 14.

Распределение состояний устройств по глобальной сети
Поскольку протокол XMPP предназначен (или, по крайней мере, позволяет) использовать его в глобальных сетях, мы можем иметь системы Asterisk в разных физических местоположениях, которые передают информацию о состоянии устройств друг другу (см. Рисунок 22-7). При реализации Corosync библиотека будет использоваться в каждой системе, что позволит им распространять информацию о состоянии устройств. В сценарии XMPP центральный сервер (или кластер серверов) используется для распределения состояний между всеми блоками Asterisk в кластере. В настоящее время лучшим приложением для этого является сервер Tigase XMPP, поскольку он поддерживает события PubSub. Хотя другие серверы XMPP могут так же поддерживать их в будущем, известно, что в настоящее время работает только Tigase.
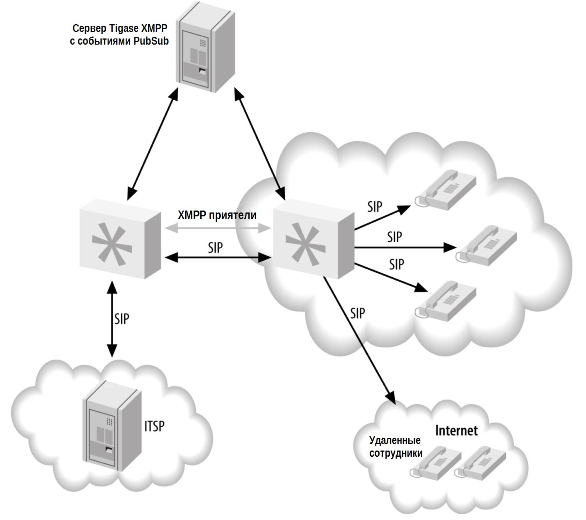
В XMPP очереди могут находиться в разных физических местах, а удаленные офисы могут принимать вызовы из основного офиса или наоборот. Это обеспечивает еще один уровень избыточности, поскольку если основной офис отключается и ITSP настроен таким образом, чтобы переключаться на другой офис, вызовы могут распределяться между этими офисами до тех пор, пока основной не перейдет в рабочий режим. Это очень увлекательно для многих, поскольку добавляет слой функциональности, который ранее не был доступен, и большинство из них можно сделать с относительно минимальной конфигурацией.
Преимущество XMPP в распределении состояний устройств состоит в том, что можно распределять состояние по нескольким физическим местоположениям, что невозможно с Corosync. Недостатком является то, что его сложнее настроить (так как вам нужен внешний сервис, на котором работает сервер Tigase XMPP), чем реализацию Corosync.
Дополнительную информацию о настройке распределенных состояний устройств с помощью XMPP можно найти в разделе «Использование XMPP» в Главе 14.
Несколько очередей, несколько местоположений
Теперь давайте проявим творческий подход и используем различные инструменты, которые мы обсуждали в предыдущих разделах, для построения инфраструктуры распределенных очередей. Рисунок 22-8иллюстрирует пример установки, где у нас есть пять серверов Asterisk, запущенных другим кластером, используемым для распределения/маршрутизации вызовов в различные очереди, которые мы настроили. Наш ITSP отправляет вызовы в кластер маршрутизации (который может быть чем-то вроде Kamailio, или даже на несколько серверов Asterisk, реализующих DUNDi или какой-либо другой метод для маршрутизации и распределения вызовов), который затем отправляет вызовы в соответствии с одной из трех систем Asterisk, в которых наши очереди настроены. Каждый сервер обрабатывает свою очередь, такую как sales, technical support и returns. Эти серверы, в свою очередь, используют агентов, расположенных в двух разных физических местах. Устройства агентов регистрируются на их собственных локальных серверах регистрации (которые также могут выполнять другие функции).

Мы не показываем все аспекты системы, чтобы сохранить диаграмму простой, но в этом случае мы будем использовать систему распространения состояний устройств XMPP, поскольку подразумеваем, что агенты распределены по нескольким физическим местоположениям.
Все агенты в разных местах могут быть загружены в одну или несколько очередей и, поскольку мы распространяем информацию о состоянии устройств, каждая очередь будет знать текущее состояние агентов в очереди и будет только распределять вызывающих абонентов агентам, в зависимости от ситуации. Кроме того, мы можем настроить штрафы для очередей и/или для агентов, чтобы доставлять вызывающих абонентов лучшим агентам, если они доступны, и использовать других агентов только когда все лучшие агенты заняты (для получения дополнительной информации о штрафах и приоритетах, см. «Расширенные очереди» в Главе 13).
Мы можем добавить больше агентов в систему, добавив больше серверов в кластер либо в том же местоположении, либо в дополнительных физических местах. Мы также можем увеличить количество поддерживаемых очередей, добавив больше серверов, каждый из которых обрабатывает свою очередь или очереди.

Недостатком использования этой системы является способ разработки приложения Queue(). Queue() является одним из старых приложений в Asterisk, и, к сожалению, оно не поспевает за темпами развития в области распределения состояний устройств, поэтому нет способа распределить одну и ту же Queue() по нескольким блокам. Например, предположим что у вас есть очереди продаж в двух системах. Если вызывающий абонент входит в очередь продаж в первой системе Asterisk, а затем другой вызывающий абонент входит в очередь продаж во втором блоке, между этими очередями не будет распределяться информация о том, кто первый, а кто второй в очереди. Две очереди эффективно разделены. Возможно, будущие версии Asterisk добавят эту возможность, но в настоящее время она не поддерживается. Мы упоминаем об этом, чтобы вы могли планировать свою систему соответственно.
Поскольку очереди в некоторых реализациях (таких как call-центры) могут потребоваться для обработки нескольких вызовов одновременно, требования к обработке и загрузке для одной системы могут быть довольно высокими. Имея возможность использовать одни и те же ресурсы агента в нескольких системах, мы можем распределять наших абонентов между несколькими блоками, значительно снижая требования к обработке, предъявляемые к любой отдельной системе. Больше не нужно чтобы это все делала одна система — мы можем распределять различные компоненты системы на разные сервера.
Заключение
В этой главе мы рассмотрели, как можно преобразовать традиционную (не Asterisk) систему телефонии в распределенный call-центр. Попутно мы рассмотрели как колл-центр с несколькими местоположениями может превратиться в систему с сотнями мест в разных физических локациях.
В то время как способность развивать свой бизнес и планировать будущее имеет решающее значение, также важно не создавать систему, которая является более сложной, чем должна быть. Чем дальше вы идете, и чем более распределенную систему строите, тем больше времени потребуется, чтобы оторваться от Земли и тем труднее будет выполнить все то, что важно, при возникновении изменений— таких как тестирование, внедрение изменений, и поддержка синхронизации вещей. Если ваша система никогда не выйдет за пределы 40-местного колл-центра, не стройте ее на 500 мест. В этом случае все что вы делаете добавляет затраты и сложность для размещения системы в масштабе, который никогда не будет полностью реализован.
Построение простой системы сейчас и планирование на будущее того, как вы собираетесь туда попасть (особенно если вы можете сделать это в итерациях, без необходимости разрывать всю инфраструктуру на части или начинать с нуля) поможет вам запуститься и заработать быстрее. По мере того как вы растете, вы можете добавить больше частей и определить, правильный ли подход принимаете. Если неправильный, то сможете вернуться и переделать проблемную часть. Такой подход может избавить вас от многих головных болей в будущем, когда вы понимаете, что не нужно переделывать всю сложную систему из-за какого-то требования, которое вы не предвидели вначале.
Мы также упомянули некоторые преимущества распределенной системы с удаленными сотрудниками, такие как улучшение морального духа сотрудников и экономия средств. Вы можете использовать существующие у ваших сотрудников интернет-соединения, аппаратное обеспечение и электричество, что может сэкономить деньги компании, и ваши сотрудники выиграют, избегая обострения и затрат на поездку в офис каждый день. Хотя не все ситуации допускают такой сценарий, стоит изучить будет ли поддержка удаленных сотрудников полезна для вашего бизнеса.
Наконец, распространение состояний устройств может открыть для вашей компании целый мир возможностей, позволив ей выйти за рамки единой системы Asterisk, которая делает все. Выход из функциональности в несколько блоков теперь является реальностью, и к ней можно подойти с уверенностью, которую раньше не видели.
1К сожалению, cdr_odbc в настоящее время не поддерживает отработку отказа.
Интерфейс шлюза Asterisk (AGI) ГЛАВА 20.
Распределённое универсальное распознавание номеров (DUNDi)

Остались вопросы?
Я - Кондрашин Игорь, менеджер компании Voxlink. Хотите уточнить детали или готовы оставить заявку? Укажите номер телефона, я перезвоню в течение 3-х секунд.
категории
- DECT
- Linux
- Вспомогательный софт при работе с Asterisk
- Интеграция с CRM и другими системами
- Интеграция с другими АТС
- Использование Elastix
- Использование FreePBX
- Книга
- Мониторинг и траблшутинг
- Настройка Asterisk
- Настройка IP-телефонов
- Настройка VoIP-оборудования
- Новости и Статьи
- Подключение операторов связи
- Разработка под Asterisk
- Установка Asterisk
VoIP оборудование

Fanvil X3S
3 900 руб

Fanvil X3S
2 990 руб
-
Fanvil X3S
2 990 руб
-
Fanvil X3S
2 990 руб
-
Fanvil X3S
2 990 руб
-
Fanvil X3S
2 990 руб
ближайшие курсы

Новые статьи









10 доводов в пользу Asterisk
Распространяется бесплатно.
Asterisk – программное обеспечение с открытым исходным кодом, распространяется по лицензии GPL. Следовательно, установив один раз Asterisk вам не придется дополнительно платить за новых абонентов, подключение новых транков, расширение функционала и прочие лицензии. Это приближает стоимость владения станцией к нулю.
Безопасен в использовании.
Любое программное обеспечение может стать объектом интереса злоумышленников, в том числе телефонная станция. Однако, сам Asterisk, а также операционная система, на которой он работает, дают множество инструментов защиты от любых атак. При грамотной настройке безопасности у злоумышленников нет никаких шансов попасть на станцию.
Надежен в эксплуатации.
Время работы серверов некоторых наших клиентов исчисляется годами. Это значит, что Asterisk работает несколько лет, ему не требуются никакие перезагрузки или принудительные отключения. А еще это говорит о том, что в районе отличная ситуация с электроэнергией, но это уже не заслуга Asterisk.
Гибкий в настройке.
Зачастую возможности Asterisk ограничивает только фантазия пользователя. Ни один конструктор шаблонов не сравнится с Asterisk по гибкости настройки. Это позволяет решать с помощью Asterisk любые бизнес задачи, даже те, в которых выбор в его пользу не кажется изначально очевидным.
Имеет огромный функционал.
Во многом именно Asterisk показал какой должна быть современная телефонная станция. За многие годы развития функциональность Asterisk расширилась, а все основные возможности по-прежнему доступны бесплатно сразу после установки.
Интегрируется с любыми системами.
То, что Asterisk не умеет сам, он позволяет реализовать за счет интеграции. Это могут быть интеграции с коммерческими телефонными станциями, CRM, ERP системами, биллингом, сервисами колл-трекинга, колл-бэка и модулями статистики и аналитики.
Позволяет телефонизировать офис за считанные часы.
В нашей практике были проекты, реализованные за один рабочий день. Это значит, что утром к нам обращался клиент, а уже через несколько часов он пользовался новой IP-АТС. Безусловно, такая скорость редкость, ведь АТС – инструмент зарабатывания денег для многих компаний и спешка во внедрении не уместна. Но в случае острой необходимости Asterisk готов к быстрому старту.
Отличная масштабируемость.
Очень утомительно постоянно возвращаться к одному и тому же вопросу. Такое часто бывает в случае некачественного исполнения работ или выбора заведомо неподходящего бизнес-решения. С Asterisk точно не будет такой проблемы! Телефонная станция, построенная на Asterisk может быть масштабируема до немыслимых размеров. Главное – правильно подобрать оборудование.
Повышает управляемость бизнеса.
Asterisk дает не просто набор полезных функций, он повышает управляемость организации, качества и комфортности управления, а также увеличивает прозрачность бизнеса для руководства. Достичь этого можно, например, за счет автоматизации отчетов, подключения бота в Telegram, санкционированного доступа к станции из любой точки мира.
Снижает расходы на связь.
Связь между внутренними абонентами IP-АТС бесплатна всегда, независимо от их географического расположения. Также к Asterisk можно подключить любых операторов телефонии, в том числе GSM сим-карты и настроить маршрутизацию вызовов по наиболее выгодному тарифу. Всё это позволяет экономить с первых минут пользования станцией.

Подпишийтесь и получайте
только свежие новости и материалы