База знаний
База знаний  IP-АТС
IP-АТС  Оборудование
Оборудование  О нас
О нас Мониторинг и настройка кластера на Centos7
В предыдущей статье Сборка кластера на Centos 7 мы установили все необходимые пакеты для сборки кластера, а также собрали его. Далее необходимо настроить все необходимые сервисы, самое главное для нас это репликация DRBD и общий виртуальный IP адрес для доступа к нашему кластеру с одного ip адреса. Сначала я хотел бы рассказать подробнее об утилите […]

В предыдущей статье Сборка кластера на Centos 7 мы установили все необходимые пакеты для сборки кластера, а также собрали его. Далее необходимо настроить все необходимые сервисы, самое главное для нас это репликация DRBD и общий виртуальный IP адрес для доступа к нашему кластеру с одного ip адреса.
Сначала я хотел бы рассказать подробнее об утилите pcs. Pcs управляется как через консоль командной строки, так и через веб интерфейс. Веб интерфейс у него располагается по умолчанию на порту 2224. Давайте его рассмотрим более подробно.
Переходим по адресу https://192.168.32.19:2224
Перед нами откроется веб интерфейс со страницей авторизации. Тут логин будет hacluster и пароль от этой учетной записи.
Введем команду
# pcs cluster status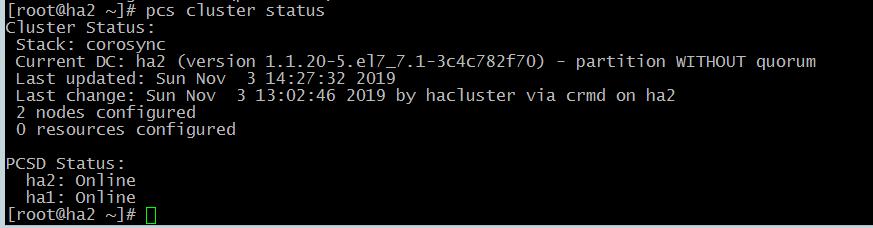
На скриншоте мы видим следующее:
- Stack: corosync – кластер построен сиспользованием Corosync
2. Current DC: ha2 (version 1.1.20-5.el7_7.1-3c4c782f70) — partition WITHOUT quorum — в качестве главного контроллера выбрана вторая нода. Также указана версия контроллера. В конфигурации этого кластера кворум не учавствует. Он отключен.
3. Last updated: Sun Nov 3 14:27:32 2019 – дата последнего обновления
4. Last change: Sun Nov 3 13:02:46 2019 by hacluster via crmd on ha2 – дата последних изменний в конфигурации кластера
2 nodes configured – какое количество нод сконфигурировано. В данном случае 2 ноды.
5. 0 resources configured – данная запись говорит о том, что ни один ресурсу нас не сконфигурирован.
6. Также необходимо проверить корректность работы Corosync. Выполним следующую команду:
# corosync-cfgtool –s 
На скриншоте видно, что ID ноды на которой была выполнена команда 2.
В следующей строчке указан ее ip адрес 192.168.32.19
И на последней строчке мы видим, что нода активирована и ошибки отсутствуют.
Если в выводе даной команды вы видите ошибки, то начните диагностику с проверки фаервола и Selinux. Они должны быть выключены.
Далее необходимо проверить правильную работу pacemaker. Сам по себе pacemaker это набор утилит, поэтому проверим корректность запуска всех необходимых сервисов командой:
# ps axf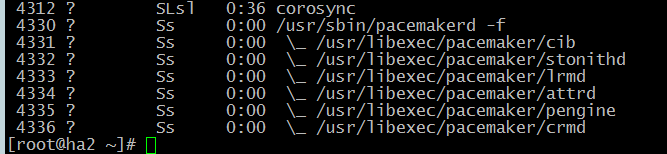
Из скриншота видно какие сервисы запущены.
Прежде чем приступать к какому либо конфигурированию сервера проверим кластер на возникновение ошибок:
# crm_verify -L –V
Как видно из скриншота у нас обнаружились ошибки. Это связано с тем, что STONITH включен в кластере по умолчанию. Но он не сконфигурирован, поэтому возникают ошибки. Мы отключим STONITH, в будущем его можно будет настроить и включить.
# pcs property set stonith-enabled=false 
Первым нашим настроенным ресурсом будет виртуальный ip адрес. Этот адрес будет мигрировать между нодами предоставляя одну точку входа к нашим ресурсам, заставляя работать несколько нод как одно целое устройство для наших сервисов.
# pcs resource create ClusterIP ocf:heartbeat:IPaddr2 ip=192.168.32.200 cidr_netmask=32 op monitor interval=15sВыше написанная команда означает: создать ресурс с именем ClusterIP используя алгоритм ресурсов ocf. Этот рессурс будет виртуальным ip адресом 192.168.32.200 с 32 маской. Также каждые 15 минут необходимо производить мониторинг работы. В случае выхода из строя ноды необходимо виртуальный ip переключить на другую ноду.
- Ocf – это стандарт которому соответствует скрипт ресурта. А также где его нати
- Heartbeat – специфичное для стандарта поле, для ресурсов ocf он сообщает кластеру, в каком пространстве имен OCF находится сценарий ресурса
- IPaddr2 – это имя сценария ресурса.
Дл того, чтобы увидеть доступные стандарты ресурсов необходимо выполнить команду:
# pcs resource standards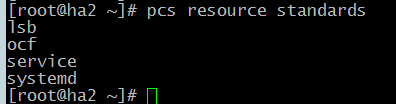
Чтобы отобразить группы сценариев ресурсов выполните команду:
# pcs resource providers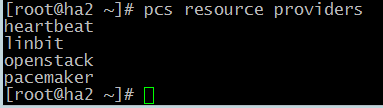
Далее посмотрим статус:
# pcs status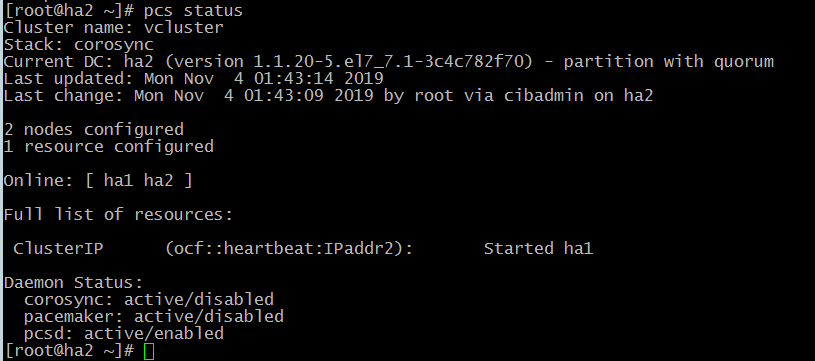
Как видно из скриншота, виртуальный ip запущен на первой ноде.
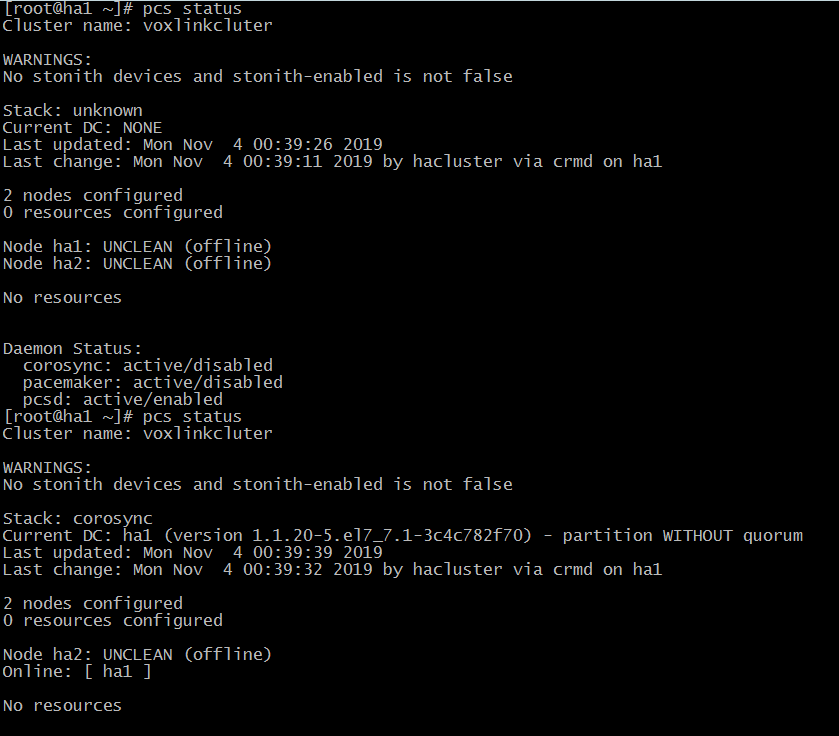
Теперь давайте сэмитируем отказ ноды,на которой запущен виртуальный ip адрес. Выполним следующую команду на отключение:
# pcs clusterstop ha1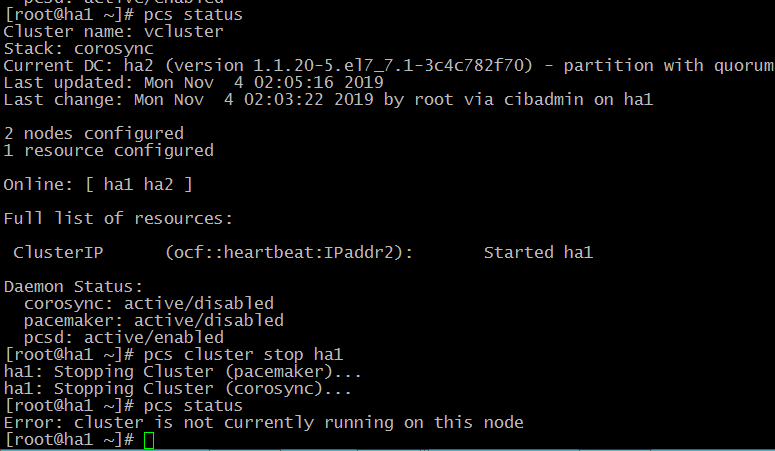
Проверим статус на второй запущенно ноду:
# pcs status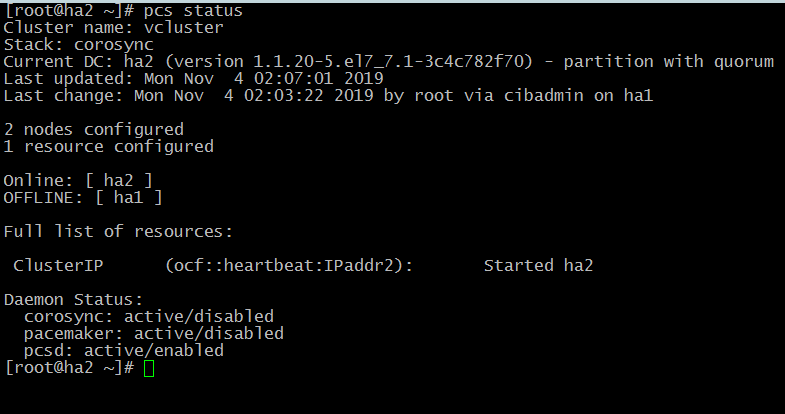
Как видим из скриншота, виртуальный ip адрес поднялся на второй ноде.
Запустим первую ноду:
# pcs cluster start ha1IP адрес восстановился на первой ноде
Переключение ресурсов между нодами иногда занимает продолжительное время, особенно если речь идет про базы данных. Следовательно не желательно чтобы ресурсы кочевали при восстановлении работы нод. Для этого предотвращения используется так называемая “Липкость” это вес ресурса, который задается на той или иной ноде:
# pcs resource defaults resource-stickiness=100В этой статье мы рассмотрели базовую диагностику и конфигурирование кластера. В следующей статье мы привяжем к кластеру DRBD.


Остались вопросы?
Я - Компаниец Никита, менеджер компании Voxlink. Хотите уточнить детали или готовы оставить заявку? Укажите номер телефона, я перезвоню в течение 3-х секунд.
категории
- DECT
- Linux
- Вспомогательный софт при работе с Asterisk
- Интеграция с CRM и другими системами
- Интеграция с другими АТС
- Использование Elastix
- Использование FreePBX
- Книга
- Мониторинг и траблшутинг
- Настройка Asterisk
- Настройка IP-телефонов
- Настройка VoIP-оборудования
- Новости и Статьи
- Подключение операторов связи
- Разработка под Asterisk
- Установка Asterisk
VoIP оборудование

Fanvil X3S
3 900 руб

Fanvil X3S
2 990 руб
-
Fanvil X3S
2 990 руб
-
Fanvil X3S
2 990 руб
-
Fanvil X3S
2 990 руб
-
Fanvil X3S
2 990 руб
ближайшие курсы

Новые статьи









10 доводов в пользу Asterisk
Распространяется бесплатно.
Asterisk – программное обеспечение с открытым исходным кодом, распространяется по лицензии GPL. Следовательно, установив один раз Asterisk вам не придется дополнительно платить за новых абонентов, подключение новых транков, расширение функционала и прочие лицензии. Это приближает стоимость владения станцией к нулю.
Безопасен в использовании.
Любое программное обеспечение может стать объектом интереса злоумышленников, в том числе телефонная станция. Однако, сам Asterisk, а также операционная система, на которой он работает, дают множество инструментов защиты от любых атак. При грамотной настройке безопасности у злоумышленников нет никаких шансов попасть на станцию.
Надежен в эксплуатации.
Время работы серверов некоторых наших клиентов исчисляется годами. Это значит, что Asterisk работает несколько лет, ему не требуются никакие перезагрузки или принудительные отключения. А еще это говорит о том, что в районе отличная ситуация с электроэнергией, но это уже не заслуга Asterisk.
Гибкий в настройке.
Зачастую возможности Asterisk ограничивает только фантазия пользователя. Ни один конструктор шаблонов не сравнится с Asterisk по гибкости настройки. Это позволяет решать с помощью Asterisk любые бизнес задачи, даже те, в которых выбор в его пользу не кажется изначально очевидным.
Имеет огромный функционал.
Во многом именно Asterisk показал какой должна быть современная телефонная станция. За многие годы развития функциональность Asterisk расширилась, а все основные возможности по-прежнему доступны бесплатно сразу после установки.
Интегрируется с любыми системами.
То, что Asterisk не умеет сам, он позволяет реализовать за счет интеграции. Это могут быть интеграции с коммерческими телефонными станциями, CRM, ERP системами, биллингом, сервисами колл-трекинга, колл-бэка и модулями статистики и аналитики.
Позволяет телефонизировать офис за считанные часы.
В нашей практике были проекты, реализованные за один рабочий день. Это значит, что утром к нам обращался клиент, а уже через несколько часов он пользовался новой IP-АТС. Безусловно, такая скорость редкость, ведь АТС – инструмент зарабатывания денег для многих компаний и спешка во внедрении не уместна. Но в случае острой необходимости Asterisk готов к быстрому старту.
Отличная масштабируемость.
Очень утомительно постоянно возвращаться к одному и тому же вопросу. Такое часто бывает в случае некачественного исполнения работ или выбора заведомо неподходящего бизнес-решения. С Asterisk точно не будет такой проблемы! Телефонная станция, построенная на Asterisk может быть масштабируема до немыслимых размеров. Главное – правильно подобрать оборудование.
Повышает управляемость бизнеса.
Asterisk дает не просто набор полезных функций, он повышает управляемость организации, качества и комфортности управления, а также увеличивает прозрачность бизнеса для руководства. Достичь этого можно, например, за счет автоматизации отчетов, подключения бота в Telegram, санкционированного доступа к станции из любой точки мира.
Снижает расходы на связь.
Связь между внутренними абонентами IP-АТС бесплатна всегда, независимо от их географического расположения. Также к Asterisk можно подключить любых операторов телефонии, в том числе GSM сим-карты и настроить маршрутизацию вызовов по наиболее выгодному тарифу. Всё это позволяет экономить с первых минут пользования станцией.

Подпишийтесь и получайте
только свежие новости и материалы