База знаний
База знаний  IP-АТС
IP-АТС  Оборудование
Оборудование  О нас
О нас Региональная маршрутизация.
Если ваша компания крупная и насчитывает много филиалов в разных регионах РФ, не совсем удобно будет для вас обрабатываться звонки Владивостока в Москве, а все из-за разницы во времени. Поэтому была придумана идея разработать функционал для определения региона звонящего, а также направления его звонка в соответствующий филиал или региональный центр федерального округа. Текущая разработка предназначена […]
Если ваша компания крупная и насчитывает много филиалов в разных регионах РФ, не совсем удобно будет для вас обрабатываться звонки Владивостока в Москве, а все из-за разницы во времени. Поэтому была придумана идея разработать функционал для определения региона звонящего, а также направления его звонка в соответствующий филиал или региональный центр федерального округа.
Текущая разработка предназначена для телефонных номеров РФ. В дальнейшем планируется её доработать до совершенства и добавить определение страны звонящего с последующей маршрутизацией вызова.
func_odbc. Назначение и использование
Для понимания всех действий, которые будут использоваться в этой статье в данном разделе будет описано краткое описание модуля func_odbc. Будет разобрано его использование. А также возможные параметры использующиеся в func_odbc.conf
Модуль func_odbc предназначен для кастомизации диалплана, при использовании обращений к базам данных по средствам ODBC коннектора. Этот модуль позволяет создавать дополнительные функции диалплана ODBC_<function’s name> для обращения к БД.
По умолчанию, при подключении этого модуля в функционал диалплана астериска добавляются две функции и одно приложение:
- ODBC_FETCH
— используется для запросов,
помеченных ,как multirow.
Возвращает идентификатор запроса, из которого можно получить данные. Т.о.
реализуется фактическая выборка результатов.
При использовании этой функции доступна переменная ${ODBC_FETCH_STATUS}. Она может принимать 2 значения SUCESS и FAILURE - SQL_ESC – позволяет передавать в SQL запрос данные, использующие в значении символ “’”.
- ODBCFinish — очищает успешно полученные данные многострочного запроса ODBC.
Далее будет дано описание параметров, используемых в файле func_odbc.conf, а также пример заполнения файла конфигурации: Первоначально оформляется название контекста в квадратных скобках. Пр. [TEST]
readhandle – указывается список DSN имён, которые установлены в файле res_odbc.conf. Этот список используется при указанном параметре readsql. Имена перебираются последовательно, пока запрос и readsl не выполнится успешно.
- writehandle — разделенный запятыми список DSN имён из res_odbc.conf, используемых при указании параметров writesql и insertsql. Правила использования, такие же как в readhandle.
- readsql – параметр выполняющийся при чтении из функции диалплана ODBC_TEST.
- writesql – параметр выполняющийся при записи из функции диалплана ODBC_TEST.
- insertql — параметр выполняющийся при добавлении из функции диалплана ODBC_TEST.
- prefix – используется для замены префикса ODBC в имени функции, для группировки используемых функций и отделения их от других запросов
- synopsis — позволяет оставить описание (synopsis) функции, если использовании команды «core show function ODBC_TEST»
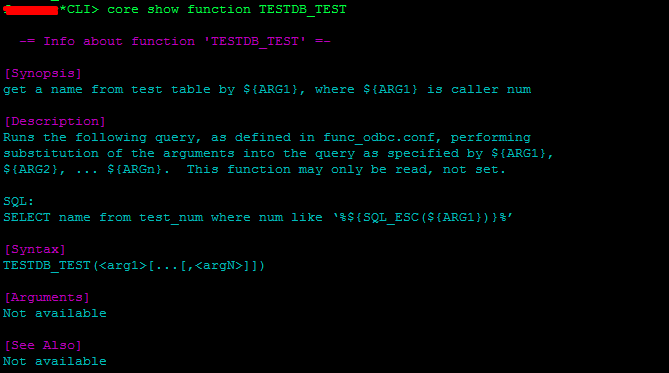
rowlimit – указывается, для ограничения количества строк возвращаемых указанной функцией.
[TEST]
prefix = TESTDB
readhandle = asteriskcdrdb
synopsis = get a name from test table by ${ARG1}, where ${ARG1} is caller num
readsql = SELECT name from test_num where num like ‘%${SQL_ESC(${ARG1})}%’
rowlimit = 1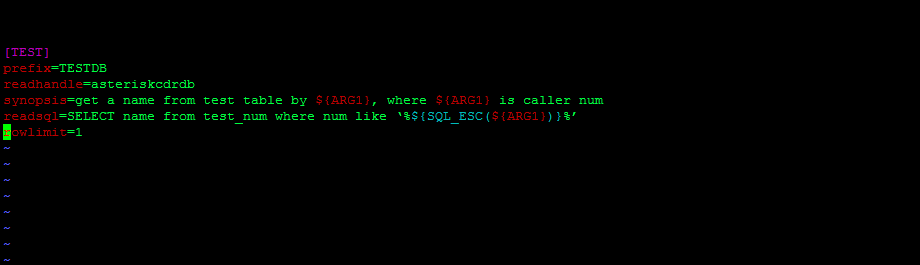
Создание задачи
Предположим, что к Asterisk подключено четыре офиса. Региональное расположение филиалов — это Екатеринбург, Хабаровск, Калининград и центральный офис — это Москва. И необходимо:
- Вызовы из Уральского Федерального Округа (УФО) направлять в филиал в Екатеринбурге.
- Вызовы из Дальневосточного Федерального Округа (ДВФО) направлять в Хабаровский филиал.
- Вызовы поступающие из Северо-Западного Федерального Округа (СЗФО) направлять в калининградский филиал.
- Все остальные вызовы направлять на Москву.
Первоначально взглянув на задачу — она кажется сложной. Но если все детально рассмотреть и составить ментальную схему, то задача становится выполнимой и легкой.
Разделим процесс на несколько пунктов:
- Составим схему звонков
- Создадим таблицу регионов использую открытые данные россвязи
- Будем выполнять маршрутизацию
Итак приступим к созданию схемы. В данной статье было принято отталкиваться от самого удаленного региона постепенно приближаясь к МСК.
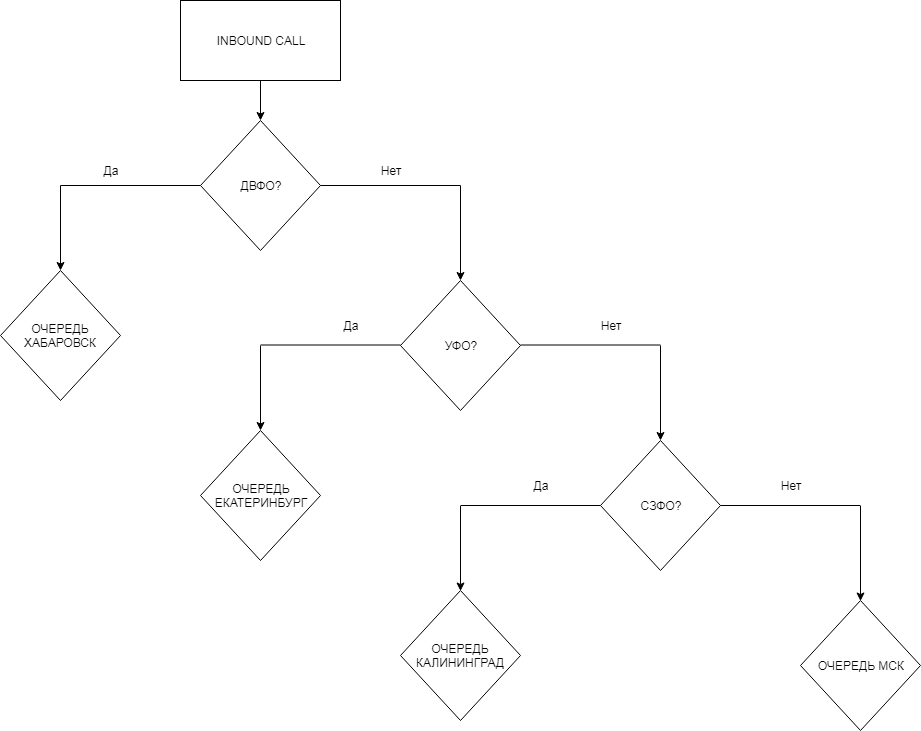
Наполнение таблицы номеров
После того, как схема была создана, перейдем к наполнению таблицы с номерами и регионами. Для начала подключившись к АТС по ssh создадим директорию regions, куда будем скачивать CSV файлы россвязи. Эта директория будет находиться по следующему пути: /usr/src/
# cd /usr/src/
# mkdir regions
# cd regions/Теперь находясь в директории regions скачаем CSV файлы с сайта россвязи. Их можно скачать к себе на ПК перейдя по этой ссылке https://rossvyaz.ru/deyatelnost/resurs-numeracii/vypiska-iz-reestra-sistemy-i-plana-numeracii и затем перенести на АТС.
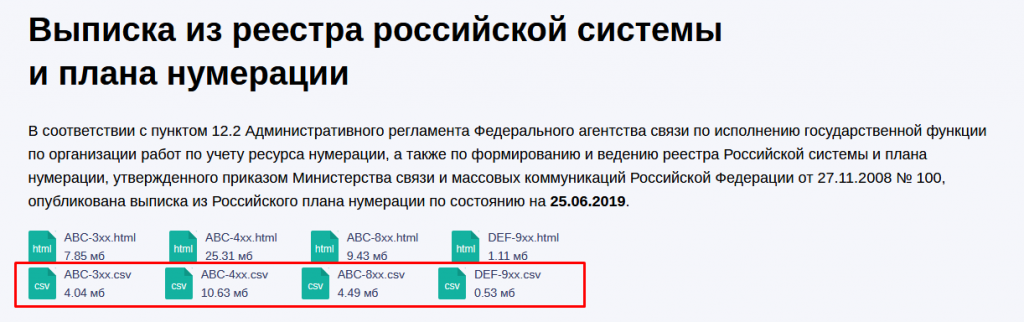
Также можно их получить из консоли АТС, используя утилиту wget.
# wget https://rossvyaz.ru/data/ABC-3xx.csv
# wget https://rossvyaz.ru/data/ABC-4xx.csv
# wget https://rossvyaz.ru/data/ABC-8xx.csv
# wget https://rossvyaz.ru/data/DEF-9xx.csvКогда закончится скачивание файлов, нужно поменять кодировку файлов из cp1251 на UTF-8 командой iconv. И командой dos2unix заменим переносы строк на Unix-овые.
# iconv -f CP1251 -t UTF-8 "ABC-3xx.csv" > "ABC-3xx_UTF-8.csv"
# dos2unix "ABC-3xx_UTF-8.csv"Таким образом это необходимо выполнить для всех скаченных файлов:
- ABC-3xx.csv
- ABC-4xx.csv
- ABC-8xx.csv
- DEF-9xx.csv
Далее необходимо отредактировать полученные файлы, а именно, удалим в них четвёртый столбец, чтобы осталися префикс, начало диапазона, конец диапазона, название оператора, регион. Для этого воспользуемся утилитой sed.
# sed -ri 's|^([^;]+);([^;]+);([^;]+);([^;]+);([^;]+);([^;]+).*$|\1;\2;\3;\5;\6|' "ABC-3xx_UTF-8.csv"Редактирование и работа с файлами закончена. Переходим к работе с Mysql. Здесь будет создана таблица где, будут храниться данные csv фалов. Также будет рассмотрен способ заполнения таблицы из скаченных файлов.
Перейдем в консоль mysql в БД asteriskcdrdb.
# mysql -u freepbxuser -p<FREEPBXUSER_PASSWORD> asteriskcdrdbИспользуя команды Mysql CREATE TABLE создадим таблицу rossvyaz.
> CREATE TABLE `rossvyaz` (
`prefix` smallint(3) NOT NULL,
`num_from` int(7) NOT NULL,
`num_to` int(7) NOT NULL,
`operator` varchar(255) NOT NULL DEFAULT "",
`region` varchar(255) NOT NULL DEFAULT "",
KEY `prefix` (`prefix`),
KEY `num_from` (`num_from`),
KEY `num_to` (`num_to`)
) DEFAULT CHARSET=utf8 ENGINE=InnoDB
В целях экономии ресурсов сервера при создании таблицы используются типы данных smallint, int иvarchar.
Далее командой LOAD DATA загружаем в созданную таблицу данные из csv файлов. Разделитель полей устанавливаем «;» и переход на новую строку указываем «\n».
> LOAD DATA INFILE '/usr/src/regions/ABC-3xx_UTF-8.csv' INTO TABLE `rossvyaz`
FIELDS TERMINATED BY ';'
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(`prefix`,`num_from`,`num_to`,`operator`,`region`);
Эту команду необходимо выполнить для каждого файла. После импорта данных перейдем к конфигурированию файла func_odbc.conf. Контекст назовем [REGION], а в параметр readsql укажем необходимую строку, для поиска нужного региона.
[REGION]
dsn=asteriskcdrdb
prefix=TEL
synopsis=Return name of region by prefix <variable>${ARG1}</variable> and by phone number <variable>${ARG2}</variable>
readsql=SELECT `region` FROM `rossvyaz` WHERE `prefix`=${SQL_ESC(${ARG1})} AND `num_from`<=${SQL_ESC(${ARG2})} AND `num_to`>=${SQL_ESC(${ARG2})} LIMIT 1;
После внесения правок, сохраняем изменения и применяем настройки командой «module reload func_odbc.so» в консоле asterisk. Если у вас все выполнено правильно вы увидите применение новой функции для астериска см. скриншот ниже.
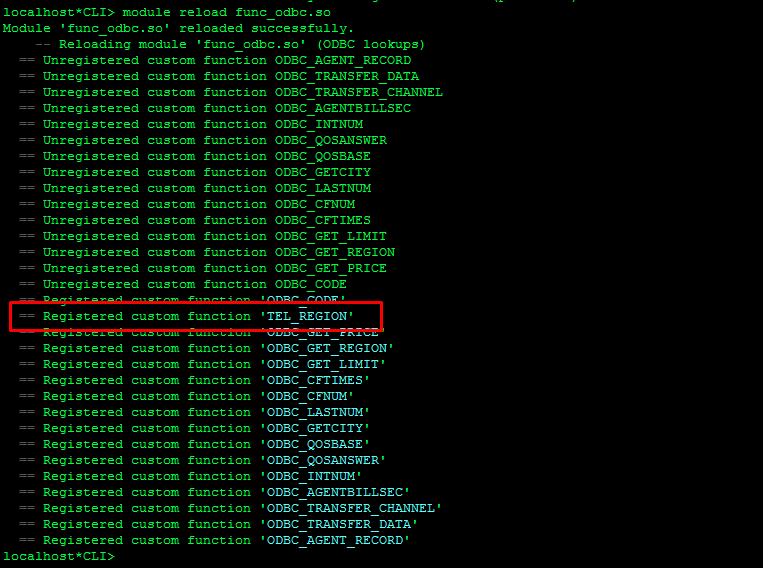
Все преднастройки выполнены, теперь переходим к настройке маршрутизации.
Соответствующее направление звонка
Перед выполнением настройки маршрутизации определим регионы относящиеся к указанным ранее округам:
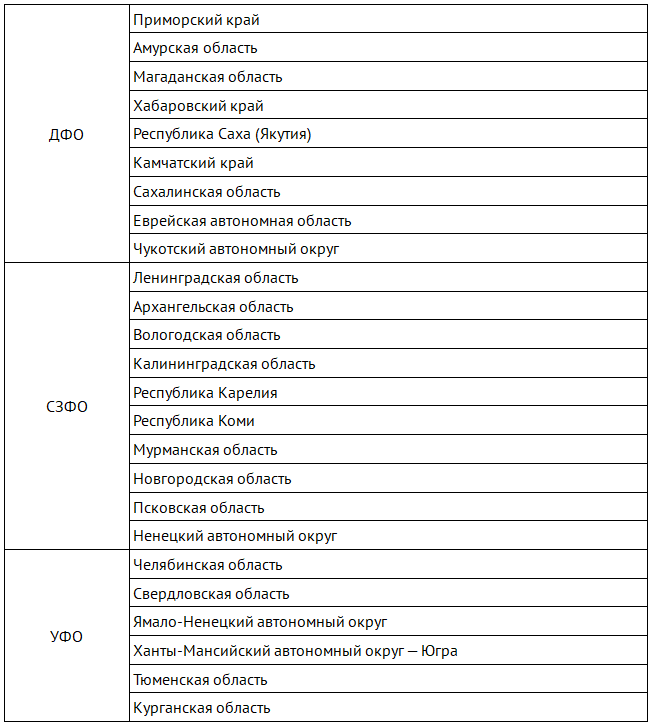
Теперь с указанными данными проще работать.
Определим номера очереди для каждого региона:
- 600 — Москва
- 601 — СЗФО
- 602 — ДФО
- 603 — УФО
Для обработки номера звонящего необходимо создать отдельный контекст, назовем его [from-trunk-pre]. В этом контексте будем производить действия с номером звонящего.
Чтобы как-то оперировать с созданной нами таблицей определим префикс и искомый номер, определим эти переменные, как PREFIX и NUMBER.
[from-trunk-pre]
exten => _X.,1,Set(__FROM_DID=${EXTEN})
same => n,Set(PREFIX=${CALLERID(num):0:3})
same => n,Set(NUMBER=${CALLERID(num):3})
После того, как были определены номер и префикс, следующей строкой обратимся к БД для поиска результата, воспользуемся зарегистрированной ранее функцией TEL_REGION. Результат будет занесен
same => n,Set(REGION=${TEL_REGION(${PREFIX},${NUMBER})})Определим несколько переменных, которые будут отвечать за совпадение с облостями, входящими в необходимые нам округа.
- SZFO_MATCH — Северо-Западный федеральный округ
- DFO_MATCH – Дальневосточный федеральный округ
- UFO_MATCH — Уральский федеральный округ
same => n,Set(SZFO_MATCH=0)
same => n,Set(DFO_MATCH=0)
same => n,Set(UFO_MATCH=0)
Далее встроенной функцией диалплана REGEX будем определять совпадение. При совпадении с указанными выше областями будем устанавливать переменную в значение 1, иначе она также останется в значении 0.
Синтаксис функции REGEX можно посмотреть командой core show function REGEX.
same => n,ExecIf(${REGEX("Санкт - Петербург" ${REGION})}?Set(SZFO_MATCH=1))
same => n,ExecIf(${REGEX("Ленинградская обл" ${REGION})}?Set(SZFO_MATCH=1))
same => n,ExecIf(${REGEX("Мурманская обл" ${REGION})}?Set(SZFO_MATCH=1))
same => n,ExecIf(${REGEX("Новгородская обл" ${REGION})}?Set(SZFO_MATCH=1))
same => n,ExecIf(${REGEX("Республика Карелия" ${REGION})}?Set(SZFO_MATCH=1))
same => n,ExecIf(${REGEX("Республика Коми" ${REGION})}?Set(SZFO_MATCH=1))
same => n,ExecIf(${REGEX("Псковская обл" ${REGION})}?Set(SZFO_MATCH=1))
same => n,ExecIf(${REGEX("Ростовская обл" ${REGION})}?Set(SZFO_MATCH=1))
same => n,ExecIf(${REGEX("Архангельская обл" ${REGION})}?Set(SZFO_MATCH=1))
same => n,ExecIf(${REGEX("Калининградская обл" ${REGION})}?Set(SZFO_MATCH=1))
Аналогично указанному выше примеру заполняем с другими округами, подставляя записанные выше области/республики и переменные DFO_MATCH и UFO_MATCH.
same => n,ExecIf(${REGEX("Хабаровск" ${REGION})}?Set(DFO_MATCH=1))
same => n,ExecIf(${REGEX("Хабаровский край" ${REGION})}?Set(DFO_MATCH=1))
same => n,ExecIf(${REGEX("Приморский край" ${REGION})}?Set(DFO_MATCH=1))
same => n,ExecIf(${REGEX("Амурская обл" ${REGION})}?Set(DFO_MATCH=1))
same => n,ExecIf(${REGEX("Магаданская обл" ${REGION})}?Set(DFO_MATCH=1))
same => n,ExecIf(${REGEX("Республика Саха" ${REGION})}?Set(DFO_MATCH=1))
same => n,ExecIf(${REGEX("Сахалинская обл" ${REGION})}?Set(DFO_MATCH=1))
same => n,ExecIf(${REGEX("Камчатский край" ${REGION})}?Set(DFO_MATCH=1))
same => n,ExecIf(${REGEX("Еврейская автономная обл" ${REGION})}?Set(DFO_MATCH=1))
same => n,ExecIf(${REGEX("Чукотский АО" ${REGION})}?Set(DFO_MATCH=1))
;--------------------------------------------------------------------
same => n,ExecIf(${REGEX("Свердловская обл" ${REGION})}?Set(UFO_MATCH=1))
same => n,ExecIf(${REGEX("Челябинская обл" ${REGION})}?Set(UFO_MATCH=1))
same => n,ExecIf(${REGEX("Ямало-Ненецкий АО" ${REGION})}?Set(UFO_MATCH=1))
same => n,ExecIf(${REGEX("Ханты - Мансийский - Югра АО" ${REGION})}?Set(UFO_MATCH=1))
same => n,ExecIf(${REGEX("Тюменская обл" ${REGION})}?Set(UFO_MATCH=1))
same => n,ExecIf(${REGEX("Курганская обл" ${REGION})}?Set(UFO_MATCH=1))
После определения всех переменных будем проверять каждую из переменных. При совпадении будем направлять на соответствующую очередь.
same => n,GotoIf($[${SZFO_MATCH} = 1]?ext-queues,601,1)
same => n,GotoIf($[${DFO_MATCH} = 1]?ext-queues,602,1)
same => n,GotoIf($[${UFO_MATCH} = 1]?ext-queues,603,1)
Чтобы заработали эти правила, необходимо в параметрах транка с оператором связи указать context=from-trunk-pre. Применяем изменения диалплана и настроек транка кнопкой «Apply Config» и проверяем.
Заключение
Таким образом мы настроили маршрутизацию на разные филиалы в зависимости от региона звонящего. Данная реализация позволит разгрузить секретаря, избавит сотрудников от лишних переводов.
Хотелось бы дополнить, что текущая схема очень примитивна, её можно расширять добавляя различные округа, районы или же города. Плюсом ко всему будет если прикрутить базу с международными номерами. Также можно дополнить всю логику привязав все к временным зонам, что избавит от пропущенных звонков.


Остались вопросы?
Я - Першин Артём, менеджер компании Voxlink. Хотите уточнить детали или готовы оставить заявку? Укажите номер телефона, я перезвоню в течение 3-х секунд.
категории
- DECT
- Linux
- Вспомогательный софт при работе с Asterisk
- Интеграция с CRM и другими системами
- Интеграция с другими АТС
- Использование Elastix
- Использование FreePBX
- Книга
- Мониторинг и траблшутинг
- Настройка Asterisk
- Настройка IP-телефонов
- Настройка VoIP-оборудования
- Новости и Статьи
- Подключение операторов связи
- Разработка под Asterisk
- Установка Asterisk
VoIP оборудование

Fanvil X3S
3 900 руб

Fanvil X3S
2 990 руб
-
Fanvil X3S
2 990 руб
-
Fanvil X3S
2 990 руб
-
Fanvil X3S
2 990 руб
-
Fanvil X3S
2 990 руб
ближайшие курсы

Новые статьи









10 доводов в пользу Asterisk
Распространяется бесплатно.
Asterisk – программное обеспечение с открытым исходным кодом, распространяется по лицензии GPL. Следовательно, установив один раз Asterisk вам не придется дополнительно платить за новых абонентов, подключение новых транков, расширение функционала и прочие лицензии. Это приближает стоимость владения станцией к нулю.
Безопасен в использовании.
Любое программное обеспечение может стать объектом интереса злоумышленников, в том числе телефонная станция. Однако, сам Asterisk, а также операционная система, на которой он работает, дают множество инструментов защиты от любых атак. При грамотной настройке безопасности у злоумышленников нет никаких шансов попасть на станцию.
Надежен в эксплуатации.
Время работы серверов некоторых наших клиентов исчисляется годами. Это значит, что Asterisk работает несколько лет, ему не требуются никакие перезагрузки или принудительные отключения. А еще это говорит о том, что в районе отличная ситуация с электроэнергией, но это уже не заслуга Asterisk.
Гибкий в настройке.
Зачастую возможности Asterisk ограничивает только фантазия пользователя. Ни один конструктор шаблонов не сравнится с Asterisk по гибкости настройки. Это позволяет решать с помощью Asterisk любые бизнес задачи, даже те, в которых выбор в его пользу не кажется изначально очевидным.
Имеет огромный функционал.
Во многом именно Asterisk показал какой должна быть современная телефонная станция. За многие годы развития функциональность Asterisk расширилась, а все основные возможности по-прежнему доступны бесплатно сразу после установки.
Интегрируется с любыми системами.
То, что Asterisk не умеет сам, он позволяет реализовать за счет интеграции. Это могут быть интеграции с коммерческими телефонными станциями, CRM, ERP системами, биллингом, сервисами колл-трекинга, колл-бэка и модулями статистики и аналитики.
Позволяет телефонизировать офис за считанные часы.
В нашей практике были проекты, реализованные за один рабочий день. Это значит, что утром к нам обращался клиент, а уже через несколько часов он пользовался новой IP-АТС. Безусловно, такая скорость редкость, ведь АТС – инструмент зарабатывания денег для многих компаний и спешка во внедрении не уместна. Но в случае острой необходимости Asterisk готов к быстрому старту.
Отличная масштабируемость.
Очень утомительно постоянно возвращаться к одному и тому же вопросу. Такое часто бывает в случае некачественного исполнения работ или выбора заведомо неподходящего бизнес-решения. С Asterisk точно не будет такой проблемы! Телефонная станция, построенная на Asterisk может быть масштабируема до немыслимых размеров. Главное – правильно подобрать оборудование.
Повышает управляемость бизнеса.
Asterisk дает не просто набор полезных функций, он повышает управляемость организации, качества и комфортности управления, а также увеличивает прозрачность бизнеса для руководства. Достичь этого можно, например, за счет автоматизации отчетов, подключения бота в Telegram, санкционированного доступа к станции из любой точки мира.
Снижает расходы на связь.
Связь между внутренними абонентами IP-АТС бесплатна всегда, независимо от их географического расположения. Также к Asterisk можно подключить любых операторов телефонии, в том числе GSM сим-карты и настроить маршрутизацию вызовов по наиболее выгодному тарифу. Всё это позволяет экономить с первых минут пользования станцией.

Подпишийтесь и получайте
только свежие новости и материалы